import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
import IPythonintroduction¶
la dataframe des iris¶
# le code
df = pd.read_csv('data/iris.csv')
IPython.display.display( df.head(2) )
IPython.display.display( df.describe() )visualisation de la dataframe - df.plot()¶
# le code
df.plot();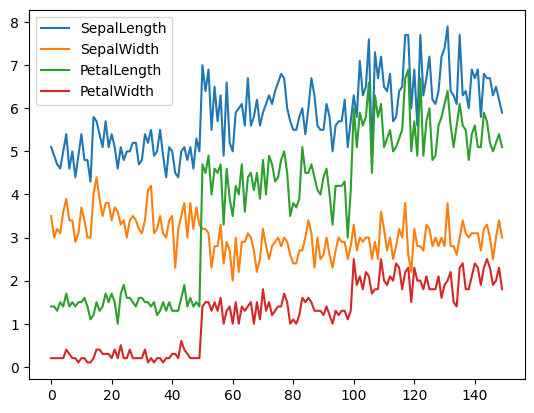
boxplots des colonnes df.boxplot¶
# le code
df.boxplot()
plt.show() # afin de ne pas superposer les plots
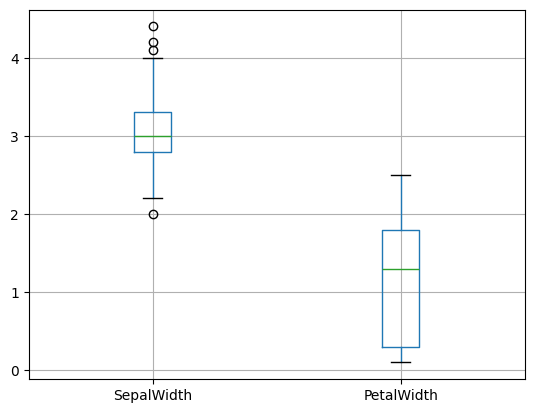
df.boxplot(['SepalWidth', 'PetalWidth']);
plt.show()
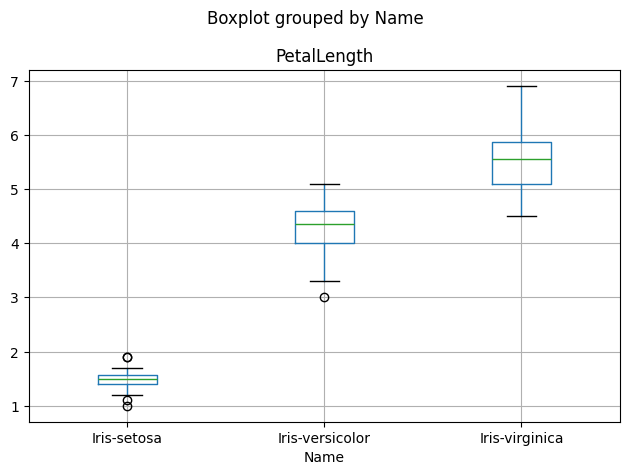
df.boxplot(['PetalLength'], by='Name')
plt.tight_layout() # le padding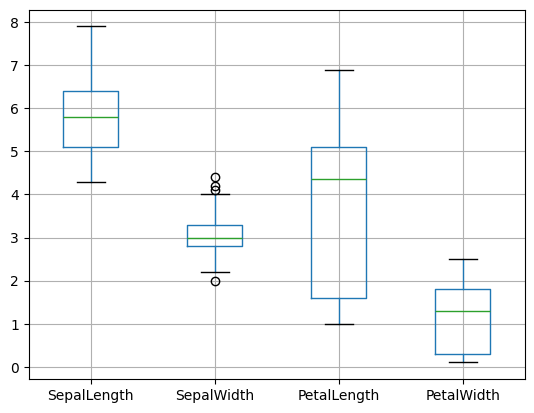
histogrammes df.hist¶
# le code
df.hist()
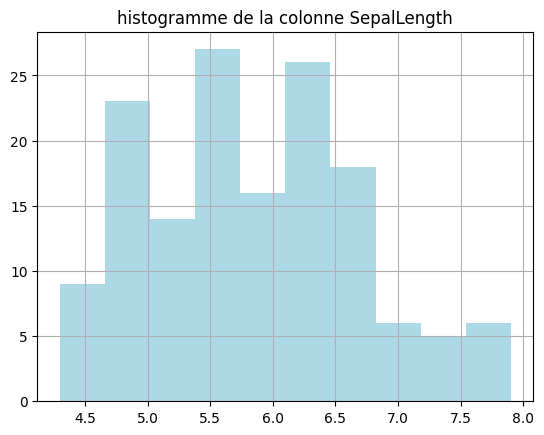
df.hist('SepalLength', bins = 10, color='lightblue')
plt.title('histogramme de la colonne SepalLength');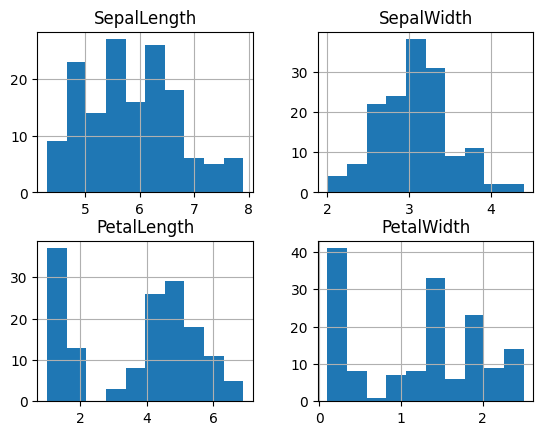
barchart df.plot.bar()¶
# le code
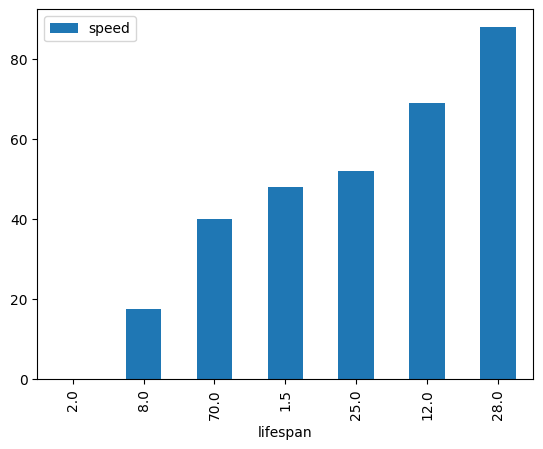
df_animals = pd.DataFrame({'speed' : [0.1, 17.5, 40, 48, 52, 69, 88],
'lifespan' : [2, 8, 70, 1.5, 25, 12, 28]},
index = ['snail', 'pig', 'elephant',
'rabbit', 'giraffe', 'coyote', 'horse'])
df_animals.plot.bar()
df_animals.plot.barh()
df_animals.plot.bar(x='lifespan', y='speed');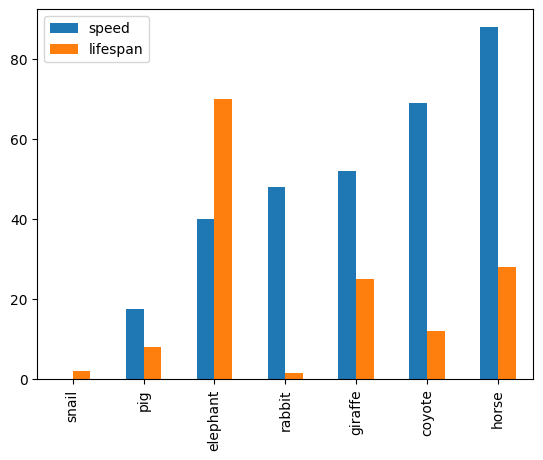
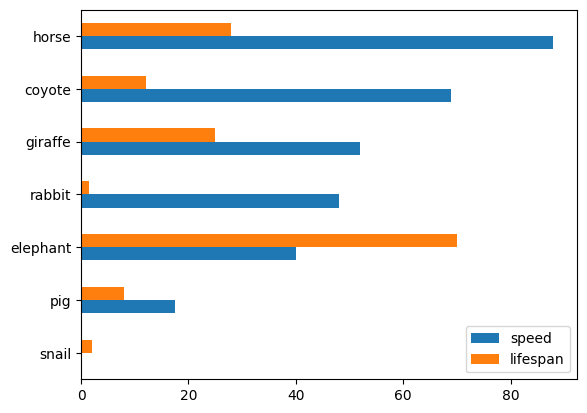
le type de la colonne 'Name'¶
# le code
IPython.display.display( df[['Name']].describe() )
df['Name'].value_counts()Name
Iris-setosa 50
Iris-versicolor 50
Iris-virginica 50
Name: count, dtype: int64#le code
df['Name'].dtype<StringDtype(storage='python', na_value=nan)>encodage de 'Name' en catégories¶
# le code
col = df['Name'].astype('category')
col.head(2)0 Iris-setosa
1 Iris-setosa
Name: Name, dtype: category
Categories (3, str): ['Iris-setosa', 'Iris-versicolor', 'Iris-virginica']# le code
df['Name-code'] = col.cat.codes
df['Name-code'].value_counts()Name-code
0 50
1 50
2 50
Name: count, dtype: int64# et en une seul ligne
df['Name-code'] = df['Name'].astype('category').cat.codesnuages de points df.plot.scatter¶
pour mettre en valeur des informations sur nos données
on peut dessiner en 2D les colonnes les unes par rapport aux autres
avec pandas.DataFrame.plot.scatter
dessinons les 'SepalLength' en fonction des 'SepalWidth'
df.plot.scatter(x='SepalLength', y='SepalWidth')on peut le faire directement en matplotlib.pyplot.plot
mais il faut alors préciser tous les paramètres (noms des axes...)
plt.scatter(df['SepalLength'], df['SepalWidth'])avec le paramètre c=
on peut changer la couleur
mais on peut aussi, indiquer une couleur par point
une idée du code couleur intéressant à utiliser ?
oui, on peut représenter ainsi la catégorie des points
chacun des 3 types d’iris, est une valeur entière différente
on va considérer cette valeur comme un code dans une table de couleurs
attention au code
0(il peut être très peu coloré dans certaines tables)
df.plot.scatter(x='SepalLength', y='SepalWidth', c='Name-code', cmap='viridis');avec matplotlib.pyplot.plot
mais vous n’avez alors que les paramètres par défaut
plt.scatter(df['SepalLength'], df['SepalWidth'], c=df['Name-code'], cmap='viridis')
plt.colorbar() # sinon pas de jolie barre de couleuravec le paramètre s= on peut changer la taille des points
ou la taille de chaque point
par exemple, donnons leur une taille proportionnelle à la largeur des pétales
plt.scatter(df['SepalLength'], df['SepalWidth'], c=df['Name-code'], s=df['PetalWidth']);ainsi sur un même dessin on peut voir 4 informations
le nuage, la couleur et la taille des points
il faut travailler un peu les paramètres pour que ce soit visible
(là la taille est trop peu différenciée, multipliez la)
# le code
df.plot.scatter(x='SepalLength', y='SepalWidth');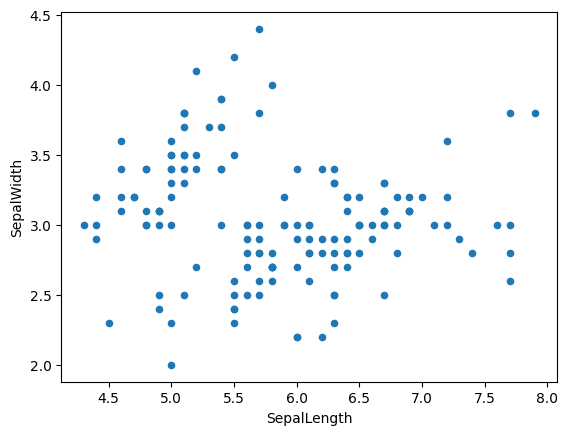
# le code
plt.scatter(df['SepalLength'], df['SepalWidth']);
# plt.xlabel('SepalLength')
# plt.ylabel('SepalWidth')
# le code
df.plot.scatter(x='SepalLength', y='SepalWidth', c='Name-code', cmap='viridis');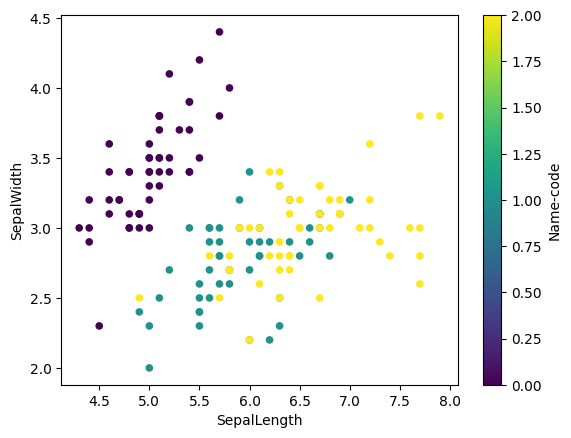
# le code
plt.scatter(df['SepalLength'], df['SepalWidth'], c=df['Name-code'], cmap='viridis')
plt.colorbar();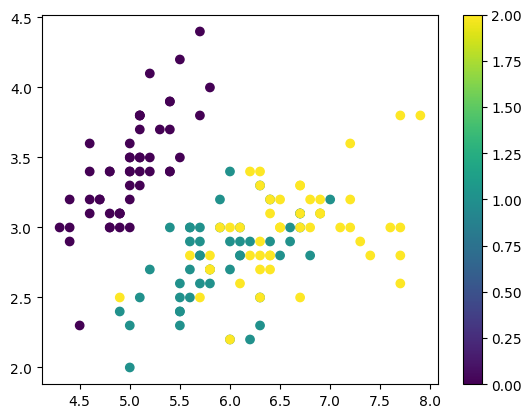
# le code
plt.scatter(df['SepalLength'], df['SepalWidth'], c=df['Name-code'], s=df['PetalWidth']*50);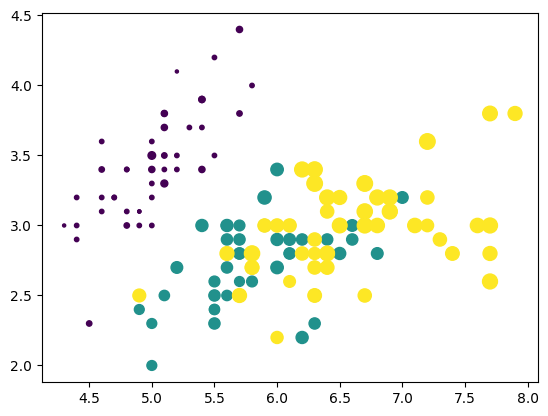
fabriquer son propre type category¶
pour les avancés
avec la technique précédente on n’a pas de contrôle sur l’ordre parmi les différentes catégories
imaginez que nous avons maintenant une colonne dont les valeurs uniques sontbad, average, good, excellent
cette colonne est clairement une colonne de type catégorie ordonnée
on peut définir son propre type catégoriel avec la fonctionpd.CategoricalDtype()
dont le paramètre ordered permet de dire si la catégorie est ordonnée ou non
en l’appliquand à la colonne des 'Names' je peux ensuite trier la dataframe
sur cette colonne
iris_ord_cat = pd.CategoricalDtype(
categories=['Iris-versicolor', 'Iris-virginica', 'Iris-setosa'],
ordered=True)
df.Name = df.Name.astype(iris_ord_cat)
df.sort_values(by='Name')iris_ord_cat = pd.CategoricalDtype(
categories=['Iris-versicolor', 'Iris-virginica', 'Iris-setosa'],
ordered=True)
iris_ord_catCategoricalDtype(categories=['Iris-versicolor', 'Iris-virginica', 'Iris-setosa'], ordered=True, categories_dtype=str)df.Name = df.Name.astype(iris_ord_cat)df.sort_values(by='Name').head(4)